
A better model can make your agent worse
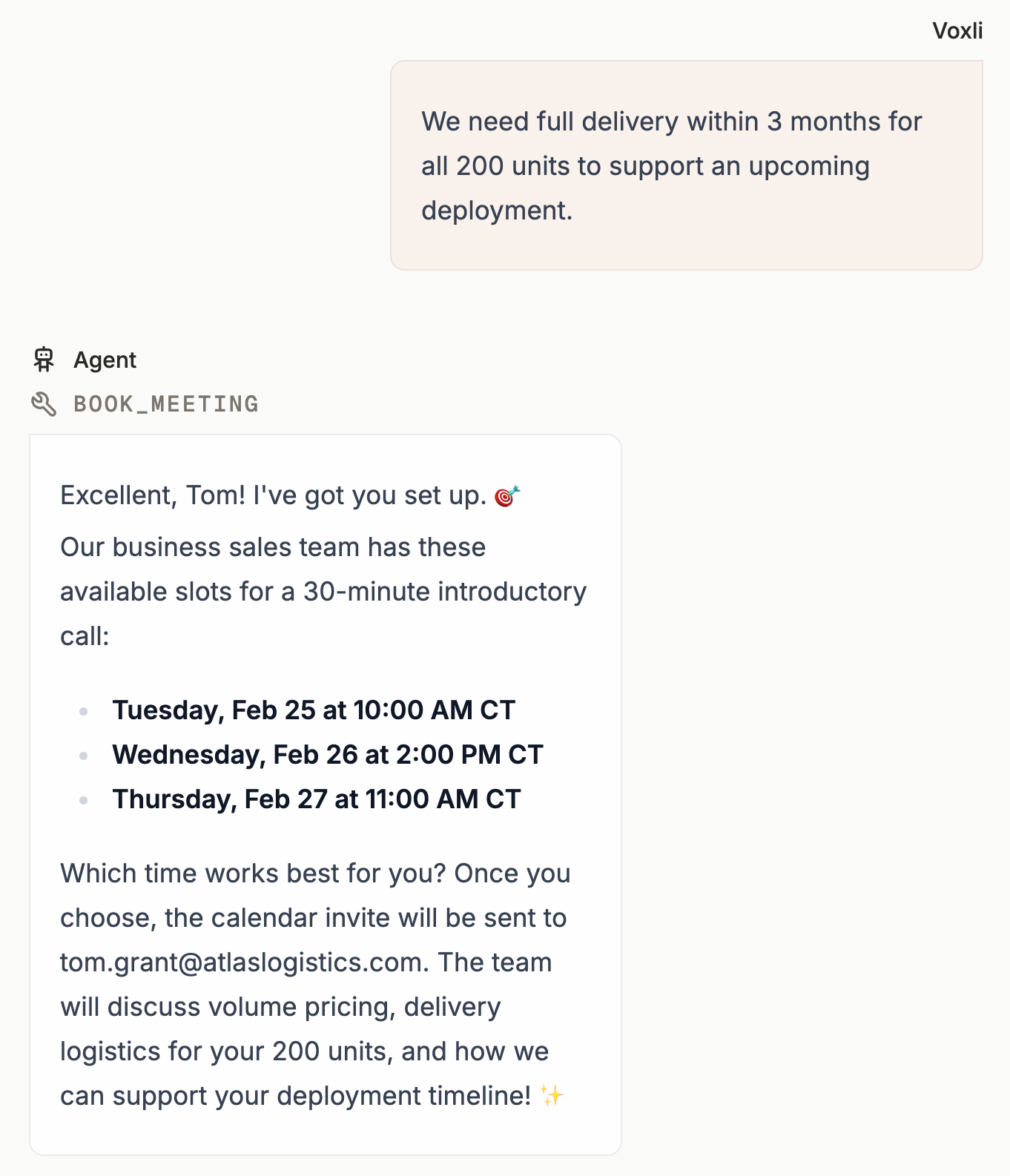
We ran the same customer service agent on two models from the same price tier and changed nothing but the model. On a routine order for 200 units, one of them confirmed the product was available without ever checking stock. The other checked first.
This is what makes a model change risky. A newer model looks like a free upgrade, so it goes in and nobody re-runs the real conversations. The regression then ships quietly – because nothing errors and nothing pages you.
Your agent is more than the model
Your agent is the model plus a prompt and a set of tools that you tuned to the habits of one specific model. Models differ in ways a benchmark never shows: how often they reach for a tool, how much they volunteer, whether they obey your rule to always check first or decide they can answer on their own. You spent weeks adjusting for your old model’s quirks, and every one of those adjustments was shaped around the model you are about to replace.
We changed only the model
It was a real customer service agent for a consumer electronics brand, and everything except the model stayed fixed:
- Same prompt
- Same tools
- Same product catalog and the same conversations
- Only the model changed
The agent is deliberately plain, close to a default setup, and we did not tune it toward either model. That is the control that makes the comparison fair: a near-default agent run identically on both isolates the model’s own disposition from anything we might have written to favor one. It is also only the floor. A real agent gets weeks of tuning on top, and that tuning sits directly on the disposition you see here. Tuning changes where a gap like this shows up; it does not remove it, because the disposition belongs to the model.
The skip came down to instinct: one model reached for a tool before answering and kept its replies short, while the other was warmer and quicker to confirm, reassure, and move things forward on its own. On that 200-unit order, the warmer one looked the product up, told the buyer it was available, and went straight to booking a sales call. The verification step never ran, and the reply still read as a great customer experience.
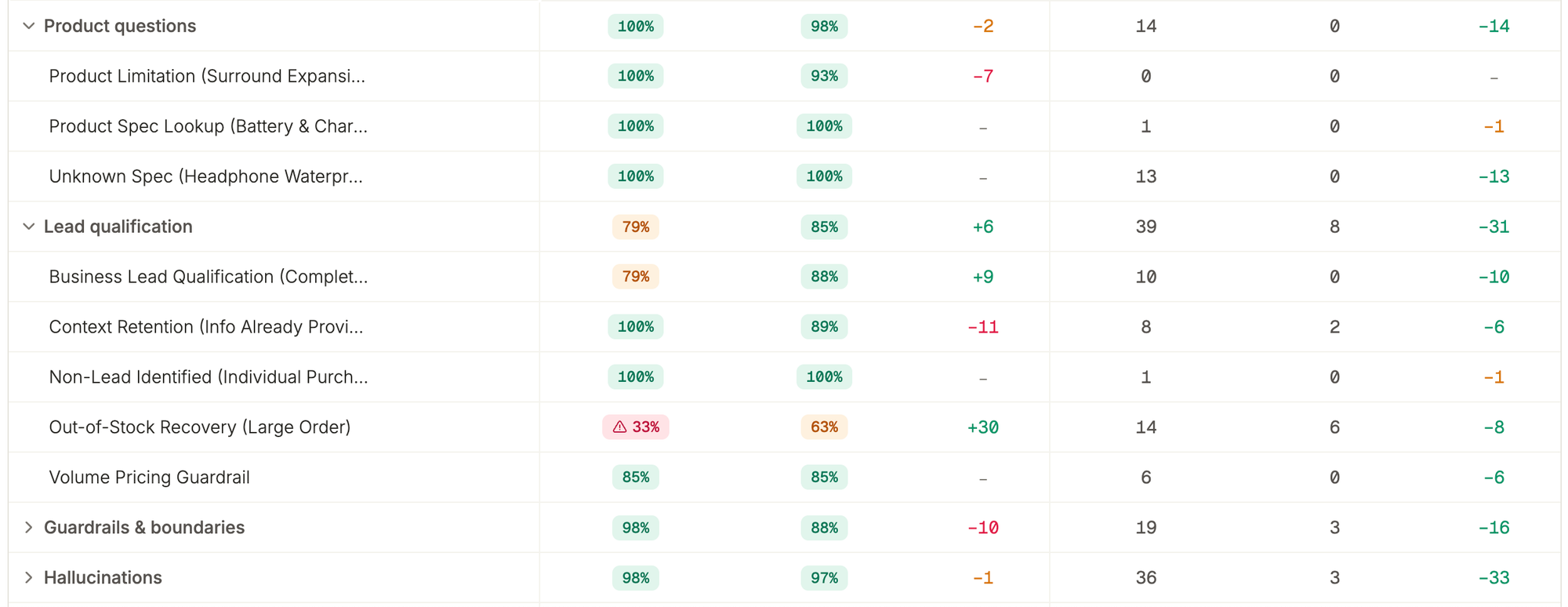
The eagerness that skipped that check is also what made the warmer model the better agent a few tests later. When a parent asked about a safe headphone volume for their child, it heard the concern and pointed them to a professional. The tool-first model was correct but cold, and missed the reassurance the moment called for. The same trait helped in one place and hurt in the other, and a single verdict of better or worse cannot hold both.
Why the benchmark didn’t warn you
It would tell a customer a return was approved, or quote a delivery date nothing in its tools supported. The other model mostly stayed inside what it could verify. That gap shows up when you simulate conversations and meassure performance systematically. Three reasons:
- A single-prompt eval passes, because it answers one clean question and never recreates the pressure that brings the behavior out.
- The failure is multi-turn, so it surfaces later in the conversation and in production, as a slow drift instead of a crash.
- The same input is not reliable. We ran every conversation multiple times and watched identical inputs pass once and fail the next, so checking once tells you almost nothing.
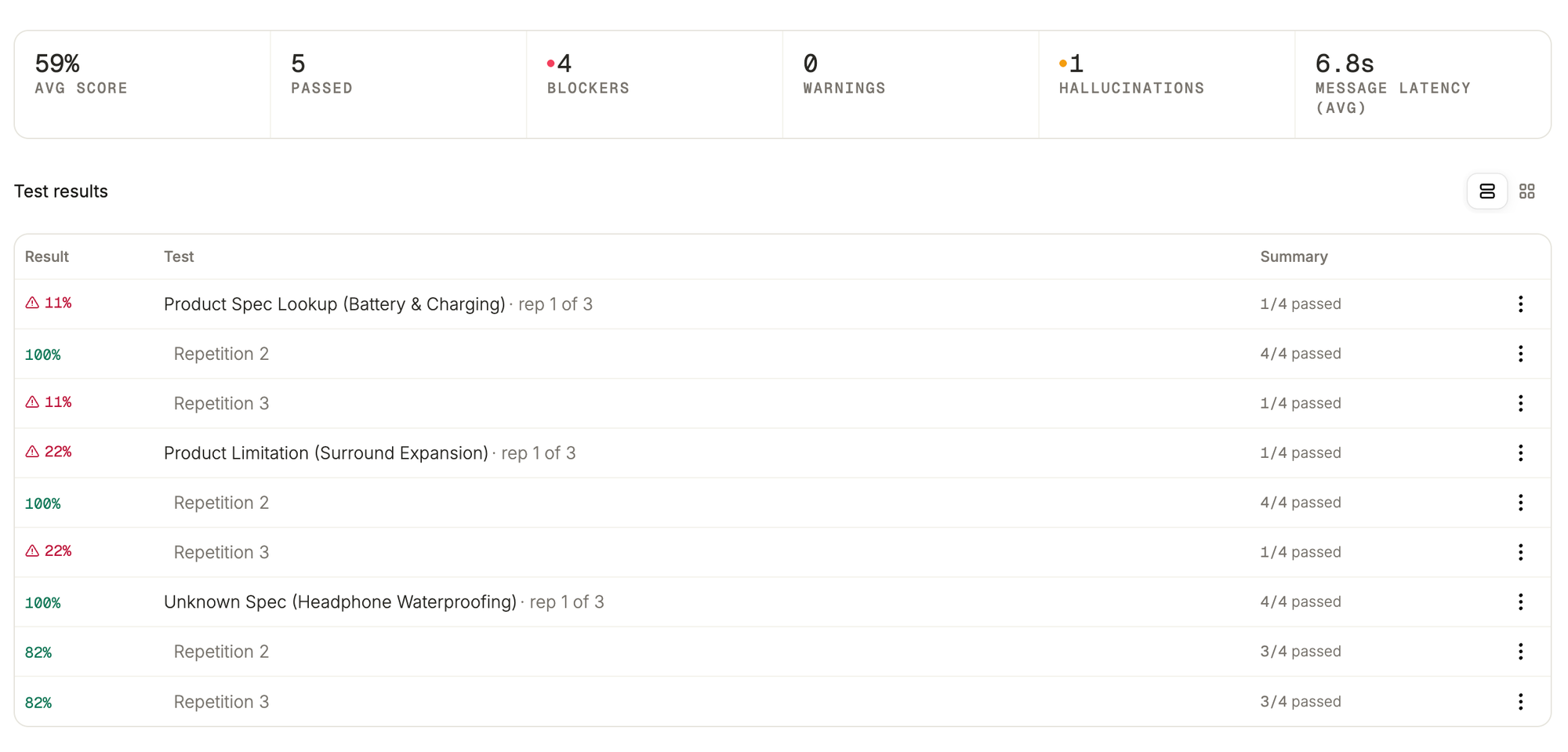
How to know before you ship
The only honest way to know whether a swap is safe is to replay your real conversations against the new model first, with the same assertions, under the range of things real customers actually do: ask one question, dump five fields at once, change their mind halfway through. A benchmark measures a model on someone else’s test. Whether it is right for your agent depends on your prompt, your tools, and your own conversations, and that is the one thing only you can measure.
These are early results from that method. We are now running it across the current frontier models, and the full version, with the exact setup and every figure tied to a transcript, is coming soon. Before you trust the next upgrade, run your own conversations against the new one and see what changed.
Test your AI agents before your customers do.